如何把「大象」塞进冰箱?
这正是现代智能辅助驾驶正在努力完成的一个命题。
我们希望车子能拥有一个像爱因斯坦一样聪明的超级大脑,但现实的尴尬是:
你不可能在后备箱里塞进一个需要液冷的服务器机柜!

当云端大模型正在加速冲刺AGI的同时,具身智能、智能驾驶等真实物理场景却正面临着一个隐性的巨大焦虑:「小」。
如何把「大模型」塞进极其有限的「小空间」车载芯片或机器人控制核心里?

这就是目前智能驾驶、具身智能、VR等领域碰到的一个现实问题:
被一块小小的芯片「卡住了脖子」。
智能驾驶正在迈向全场景智能,但车载算力平台撞上了一个核心悖论:
比如,一个在云端GPU上10毫秒就能完成的推理任务,到了车载芯片上可能要300毫秒。对自动驾驶来说,300毫秒意味着车辆在高速上「盲开」了好几米。
所有巨头,英伟达、苹果、微软、谷歌都在想办法。
但是第一个给出理论级答案的,是一家中国车企。
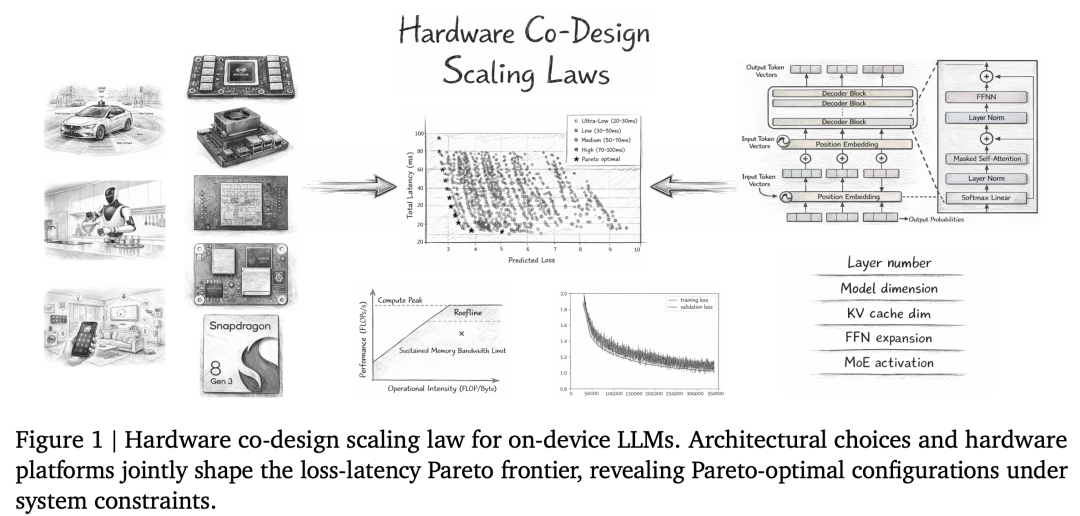
2026年2月,理想汽车基座模型MindVLA团队与国创决策智能技术研究所联合发布了一篇论文:《Hardware Co-Design Scaling Laws via Roofline Modelling for On-Device LLMs》。
提出了面向端侧大语言模型的「硬件协同设计扩展定律」。

这篇论文直面了当前最核心的挑战之一:
如何将越来越强大的大语言模型高效地部署在资源受限的「端侧设备」(如汽车、手机、机器人)上。
提到理想汽车,多数人的第一反应还是「增程式电动车的代表」。但审视其近两年的技术布局:自研5nm车规芯片马赫100、开源操作系统星环OS、自研基座大模型MindVLA、端到端智驾全栈自研。
理想正在从一家以增程技术见长的汽车公司,蜕变为一家以智能驾驶和具身智能为核心的AI公司。
而这篇刚刚发布的论文,是理解这场转型最好的注脚。
大模型「上车」,卡住了!
如何将目前「最先进的AI」装入汽车?
这里会遇到了一个巨大的矛盾:
一方面,希望车载AI模型尽可能地聪明、反应迅速,以确保驾驶安全和流畅的交互体验。这要求模型规模大、结构复杂。
另一方面,汽车内部的计算单元(芯片)受到严格的物理限制,包括功耗、散热、内存大小和成本。这要求模型必须小巧、高效。
传统的做法通常是「模型归模型,硬件归硬件」。
AI研究者设计出性能强大的模型,然后由工程师想办法在硬件上进行优化和「塞入」。
这种方式效率低下,且往往无法达到真正的最优。
这就好比为一个F1赛车引擎设计了一个巨型卡车的底盘,二者无法完美匹配,引擎性能大打折扣。
而理想这篇论文正是为了解决这个「失配」问题,他们提出了一套系统性的方法:
在设计模型之初就将硬件的能力考虑进来,实现「软硬协同设计」(Hardware Co-Design)。
软硬协同:连接模型与硬件的桥梁

如何衡量模型的「智慧」?
先来简单介绍下什么是损失-延迟帕累托前沿。
在AI领域,「损失」是衡量模型预测与真实答案之间偏差的指标。
损失越低,模型预测越准确,代表它越「聪明」、精度越高。你可以把它理解为「工作质量」。
延迟指的是AI给出反应需要多长时间。延迟越低,速度越快,代表它能做到「秒回」。你可以把它理解为「工作速度」。
帕累托前沿是一个经济学概念。
通俗地说,当你追求既要「质量高」(低损失),又要「速度快」(低延迟)时,你会遇到一个物理极限。

到了这个极限状态后,你不可能在不牺牲速度的前提下,让AI变得更聪明;也不可能在不牺牲聪明度的前提下,让AI跑得更快。
所有这些「最优的折中点」连起来的一条线,就叫「帕累托前沿」。
理想团队发现,模型的最终损失与其架构超参数(如网络深度、宽度、专家数量等)之间存在着可预测的数学关系。
通过对这个关系进行精确建模,就可以在不实际训练的情况下预测模型性能。
团队做了一件极其扎实的事——真的训了170个不同架构的Transformer模型,每个用100亿token训练,覆盖Dense(密集)和MoE(混合专家)两大类,层数4到48,宽度256到4096,MoE专家数1到64。
目的就是拟合一条精度预测公式:
给定任意一组架构超参数,直接预测验证损失——不用真的训练。
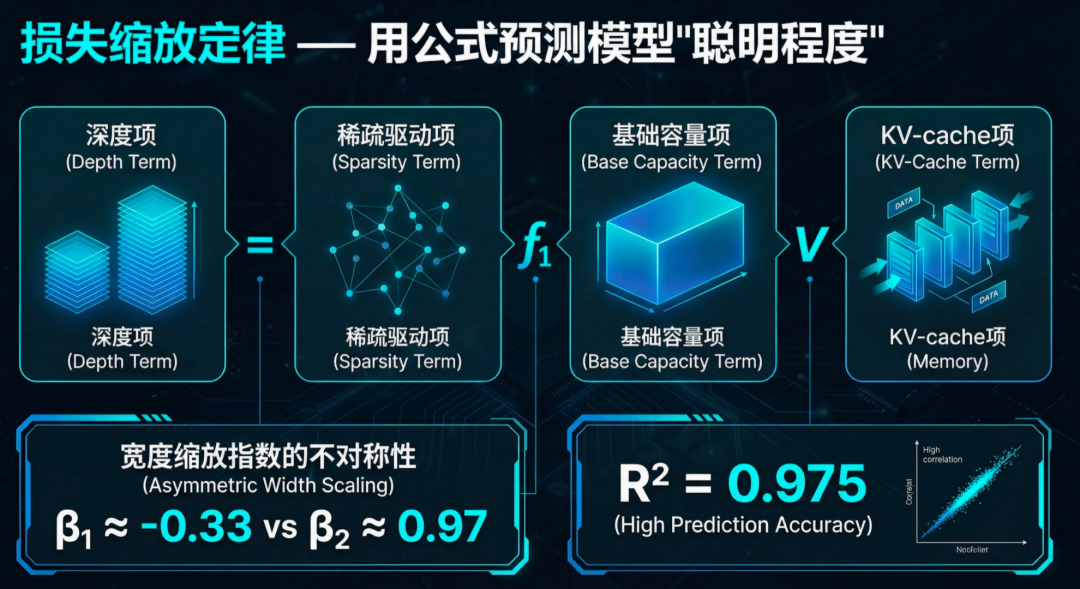
在同时包含密集和稀疏模型的异质架构空间中,这个预测精度极其惊人。
模型有多聪明,算一下就知道。
通俗地说,理想团队找到了一个「计算器」,输入一个模型的设计方案,就能算出这个模型理论上能有多聪明。
如何衡量硬件的「性能」?
对于一块芯片而言,决定其运行速度的关键因素有两个:
峰值计算能力 (FLOPS):芯片每秒能执行多少次浮点运算,如同工厂的生产线速度。
内存带宽 (Bandwidth):芯片每秒能从内存中读取多少数据,如同工厂的物料供应速度。
一个程序的运行速度,取决于它究竟是被「计算」卡住了瓶颈,还是被「内存读取」卡住了瓶颈。
Roofline模型正是这样一个经典的性能分析工具。
它可以根据一个任务的计算量和内存访问量,以及硬件的上述两个参数,精确地预测出该任务的理论运行时长,即「延迟(Latency)」。
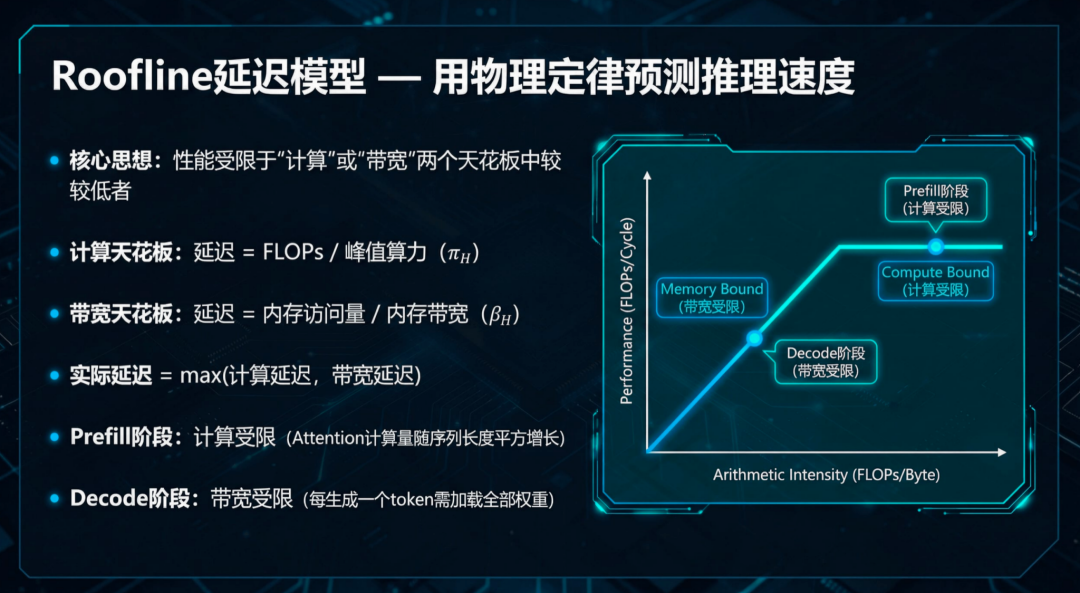
理想团队利用Roofline模型也造了一个「计算器」,输入一个模型和一个硬件平台,就能算出模型在这块芯片上跑一次需要多长时间。
团队基于经典的Roofline模型,从第一性原理推导了Transformer端到端推理延迟的完整数学表达。
研究团队特别针对车载场景做了关键扩展:
首次系统建模了KV缓存、MoE路由、注意力机制等大模型特有负载对车载SoC内存子系统的影响,在Jetson Orin/Thor平台上验证了普适性。
这个延迟模型有多高效?
20分钟内就可以评估5万+种架构配置。

模型跑多快,也算一下就知道。
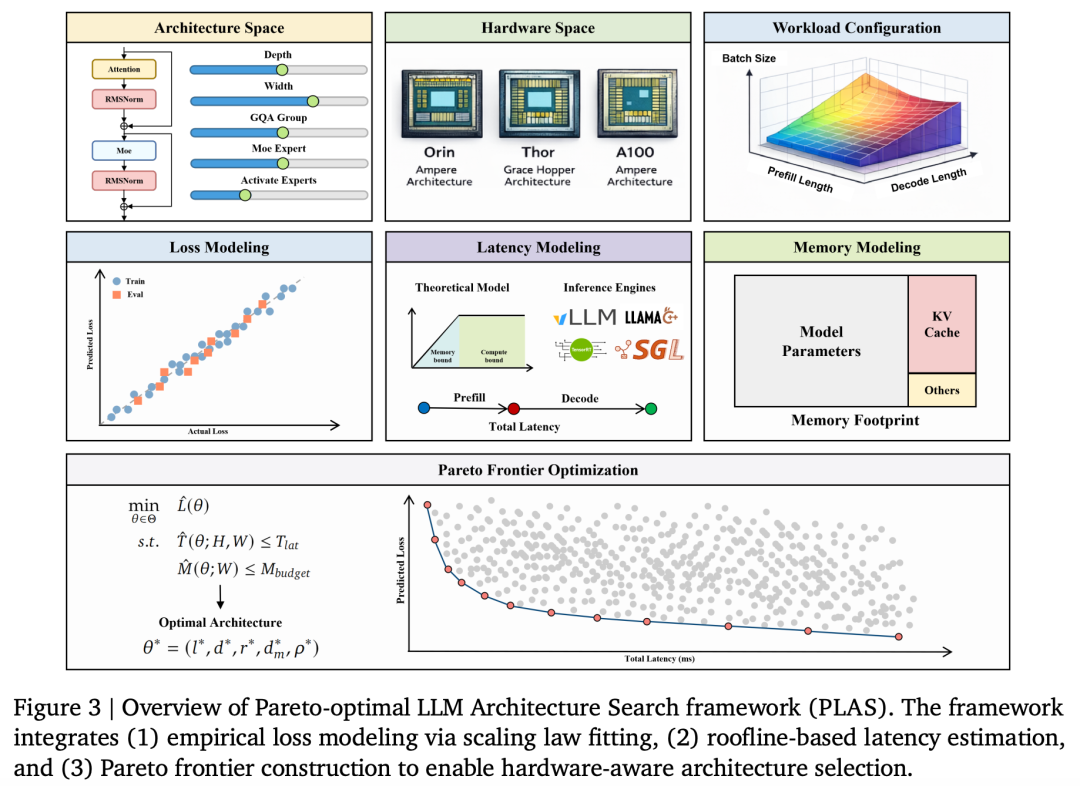
合二为一:帕累托最优搜索
接下来就是联合优化。
团队开发了PLAS框架(Pareto-optimal LLM Architecture Search):
给定芯片的算力、带宽和内存约束,自动找到使损失最小、同时延迟不超标的最优架构。

解集构成一条帕累托最优前沿——前沿上每个点,都是该延迟预算下能达到的最低损失。
你不可能在不增加延迟的情况下降低损失,也不可能在不增加损失的情况下减少延迟。
这就是「软硬协同设计定律」的本质:将模型精度和推理效率统一在同一数学框架下的联合优化理论。
这也是论文最硬核的部分:在不同硬件约束下,最优模型架构参数存在闭合解。
无需训练,给定芯片参数,直接算出模型架构最优解。
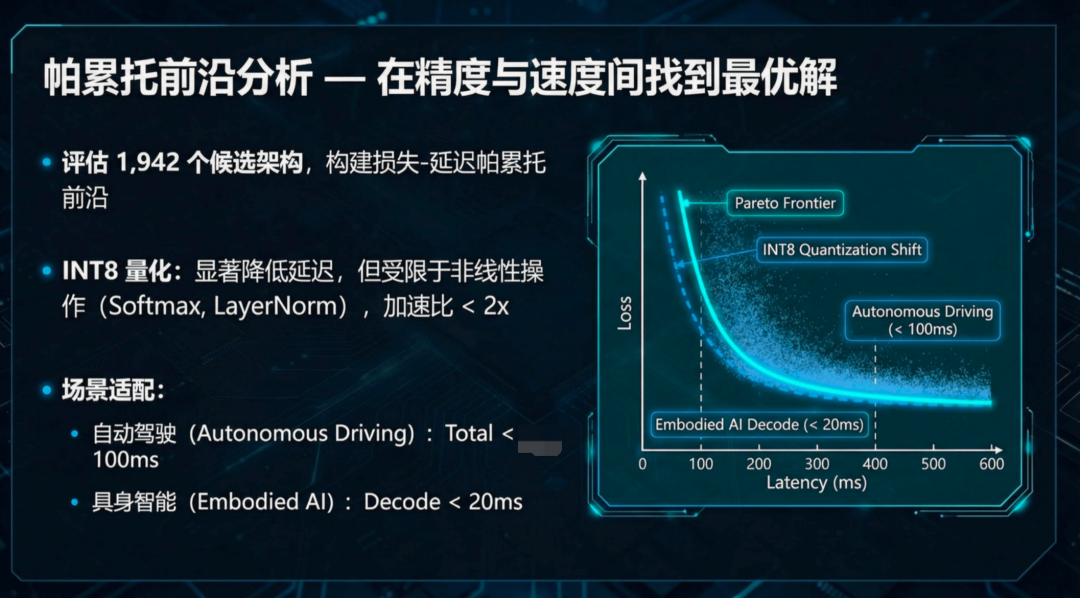
以下是团队推导出来的三个关键定理。
定理一:延迟约束下的「免费午餐」。
芯片速度是瓶颈,内存充裕(如车载高端平台)的场景下。
MoE专家越多、每次激活越少越好。

为什么叫「免费」?MoE中不管总共多少专家,每个token只激活K个来计算。
增加总专家数完全不影响推理延迟,但模型容量实打实增加了。
对自动驾驶的启示:在sub-50ms极限延迟下,应采用top-1路由,内存允许范围内最大化专家池。
定理二:内存约束下的「宽度-稀疏度定律」。
存储有限、速度够用(如4-8GB边缘设备)的场景下。
结论是模型越宽,MoE越应该稀疏。 宽度每翻一倍,最优激活率下降约2.3倍。

比如,2B参数模型推荐每次激活2个、总共16个专家;500M参数模型推荐更密集的MoE配置。
以上都是有数学证明的最优解,不是拍脑袋的数据。
定理三:双重约束下的精确处方。
延迟和内存同时紧张(实际部署最常见的情况)的场景下,论文给出了预填充和解码两种阶段各自的精确闭合解。

不管芯片什么约束组合,定律都有对应公式。
颠覆认知的关键发现
除三大定理外,论文还揭示了几个违反直觉的设计原则:
端侧batch=1场景下,帕累托最优设计100%是MoE,没有Dense模型。大多数最优配置的专家激活比例为在8~16个中激活1~2个。
「宽而浅」的最优架构形态表明,内存带宽和缓存效率往往比理论TOPS更决定实际性能。
芯片需要支持动态资源分配,而非固定流水线。
最优FFN扩展比远低于传统4×,甚至可以低于1×,芯片的矩阵乘单元和激活函数单元需要更灵活的配比。
INT8量化仅实现1.3-1.6倍而非理论2倍加速,根源在于非线性算子和精度转换开销。下一代芯片需要在指令集层面提供混合精度计算的原生支持。
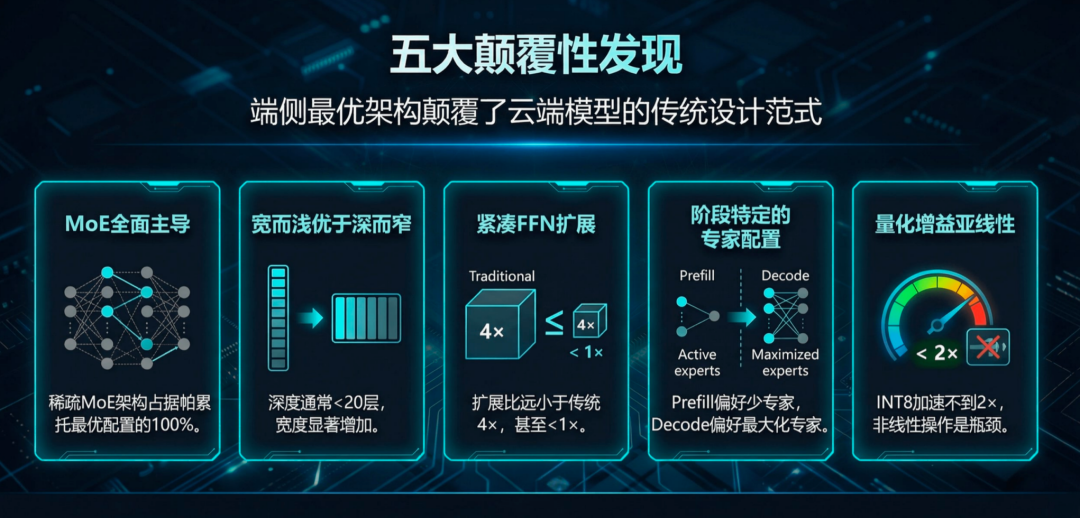
也就是说,没有通用芯片,只有场景最优芯片。
最优架构强烈依赖于具体硬件参数,从根本上证明了「算法定义芯片」的必要性。
用数据说话:19.42%的碾压
理论再漂亮,没有实验验证都是空中楼阁。
团队在NVIDIA Jetson Orin(一款代表性的端侧AI计算平台)上做了大规模验证:
通过延迟模型评估了1942种候选架构配置,精选170个进行完整训练(每个100亿token)。
这可能是端侧LLM领域规模最大的系统性架构搜索实验——没有之一。
团队选取了Qwen2.5-0.5B(通义千问5亿参数版本,端侧广泛使用的开源模型)作为基准。
先在Orin上实测其推理延迟,再从PLAS框架中选取相同延迟下的协同设计架构。
两者使用完全相同的训练数据和优化策略,公平对比。
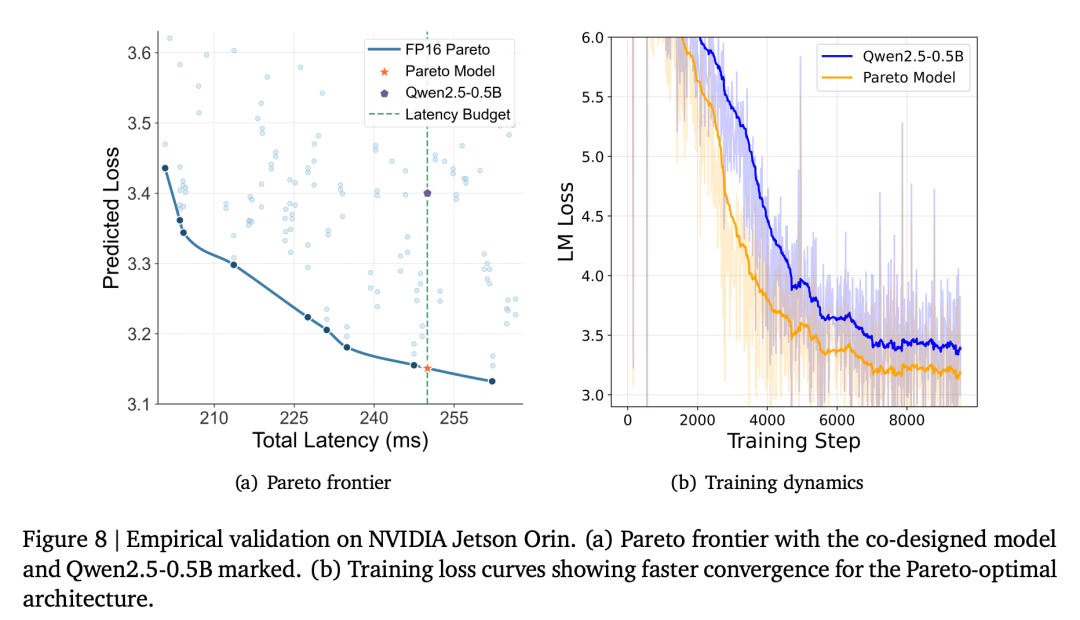
结果:
Qwen2.5-0.5B困惑度:63.14
协同设计架构困惑度:50.88
困惑度降低19.42%!

而且这不是训练终点的「碰巧」——从训练曲线看,协同设计架构全程领先,优势来自架构本身,而非随机波动。
同时给出了不同硬件平台(Jetson Orin/Thor)上的帕累托最优前沿,验证了「硬件协同设计扩展定律」的跨硬件平台泛化性。
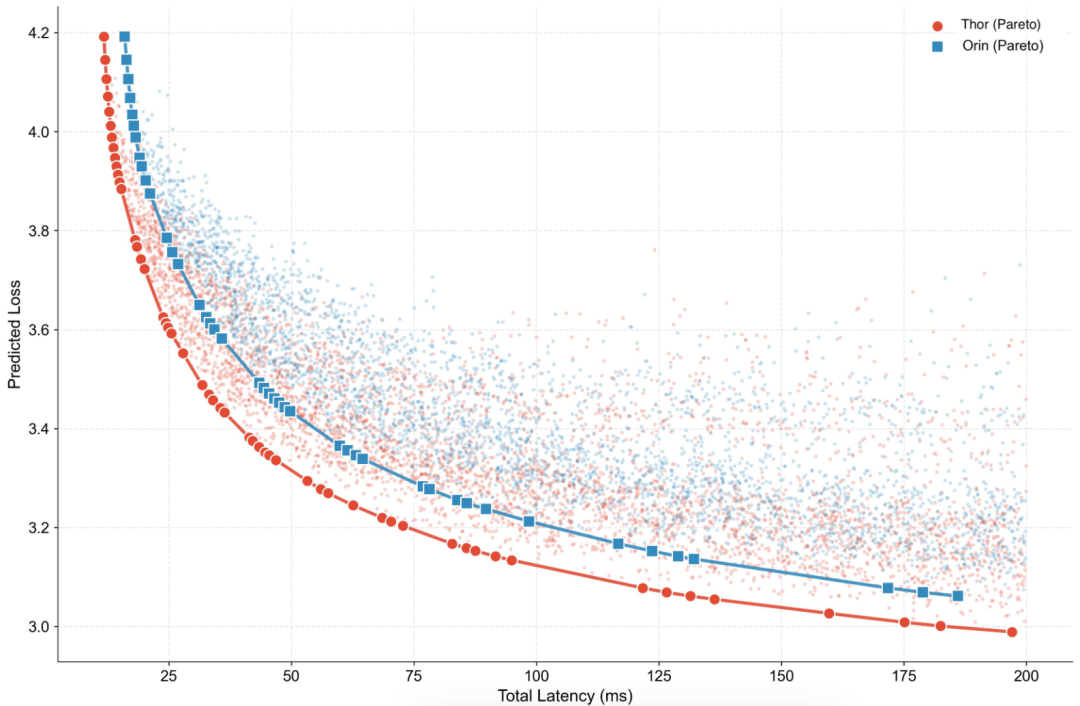
同样的芯片,跑同样快,但智商高了近20%——这就是「软硬协同设计」的力量。
另一个同样重要的数据:架构选型时间从数月压缩到一周。
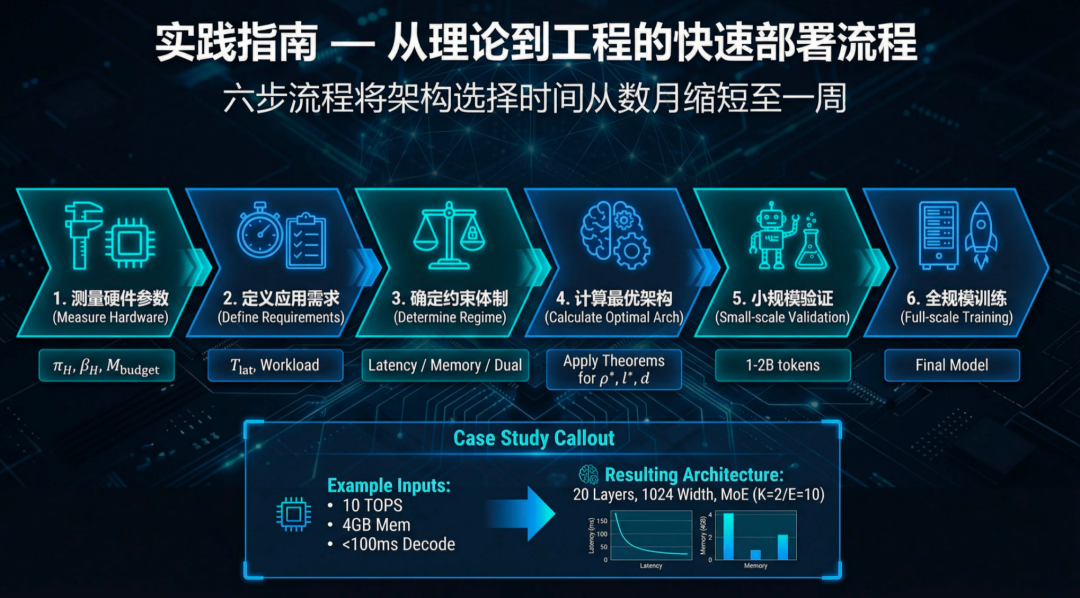
传统流程中,给一块新芯片选择最优LLM架构,需要反复训练、测试、调优,耗时数月。
有了协同设计定律后,流程变成:
输入芯片参数 → 定律计算最优架构 → 小规模验证校准 → 完成。
研发效率提升一个数量级!
这意味着当理想下一代自研芯片出来的时候,最优模型架构不需要再等数月适配期,使用「软硬协同设计定律」可以提前算出来。
端侧AI的Scaling Law
如果说,OpenAI的Scaling Law回答了「模型为何越大越聪明」。
理想这个定律回答:「在固定芯片上,模型怎么变到最聪明」。

OpenAI的Scaling Law是云端大模型繁荣的基石。
在它出现之前,训练多大的模型、用多少数据往往依赖工程师的直觉(经验主导)。

它通过严谨的数学公式证明了模型的性能与计算量、参数量、数据量之间存在可预测的幂律关系。
Scaling Law成功指导了大语言模型的迭代,使得巨头们敢于投入数亿美金去训练更大级别的模型。
而理想的Hardware Co-Design Scaling Law是向端侧迈出的关键一步。
它从约束优化理论出发推导出解析解,在给定的硬件物理极限和实际应用约束条件下,科学指导如何最优地分配端侧推理资源。
这是首个面向端侧LLM的、可操作的硬件协同设计扩展定律。
两者虽然约束条件和发力点不同,但在本质上殊途同归:
都是用数学和科学的确定性,消除了AI发展过程中的经验盲区与随机性。
从「堆算力」到「榨算力」
过去智驾竞争的叙事是「我的芯片比你大」。
但这篇论文证明:
芯片有多少TOPS和实际能发挥多少智能之间,存在巨大鸿沟。
100 TOPS的芯片,模型架构不匹配,可能只发挥30%效能。
软硬协同设计定律要做的,就是把效能利用率拉到接近理论上限。
不是比谁芯片更大,是比谁更懂怎么用芯片。这才是降维打击。
「芯片-模型」联合开发新范式
这对理想即将量产的马赫100自研芯片意义重大。
马赫100是5纳米车规级芯片,2026年将在全新理想L9搭载。
单颗马赫100的有效算力是英伟达Thor-U的3倍,全新L9的双马赫100芯片,有效算力就是Thor U的5-6倍了。

之前传统的做法是,等芯片流片回来,花数月重新适配模型。
有了协同设计定律:输入芯片参数,定律直接算出最优VLA架构——芯片还没量产,最优模型已经算出来了。
配合理想的完整技术栈来看,从芯片到定律到系统到模型——这是一个完整的技术闭环。
马赫100:提供硬件算力
协同设计定律:确保每一分算力被精准利用
星环OS:统一软件架构和开发者生态
MindVLA:落地智能辅助驾驶大模型
基于这个定律,理想的自研芯片将不再是通用AI加速器,而是专为车载VLA系统优化的「算法原生芯片」——在架构层面原生支持稀疏计算、动态资源分配和混合精度推理。
这不仅是理想汽车从算法到芯片全栈自研能力建设的关键里程碑,也为行业提供了端侧大模型部署的科学方法论。
同时也为理想汽车的下一代智能驾驶系统提供数量级的能效提升。
写在最后
摩尔定律在放缓——晶体管数量翻倍的时代正在终结。
「协同设计定律」标志着一条新曲线的开始:不靠芯片变快提升智能,靠更聪明地使用芯片提升智能。
理想团队计划开源相关代码和评测协议。
整个行业——汽车、机器人、IoT、移动端——都可以站在这个理论框架上,为自己的芯片找到最优的大模型架构。
真正的领先,从来不是简单的硬件堆砌,而是源于底层基础科学的突破。当理想率先用严谨的数学规律重构端侧 AI 的边界时,这种在底层理论上的深耕与引领,正是理想智能驾驶系统能够跨越算力瓶颈、持续领跑行业的最大底气。
在智能驾驶的下半场,能够定义底层规则的企业,才能真正主导全场景智能的未来体验。